Research Statement
I am interested in the design of reinforcement learning algorithms and approaches for the creation of safe superintelligence.
AI Leap Recap
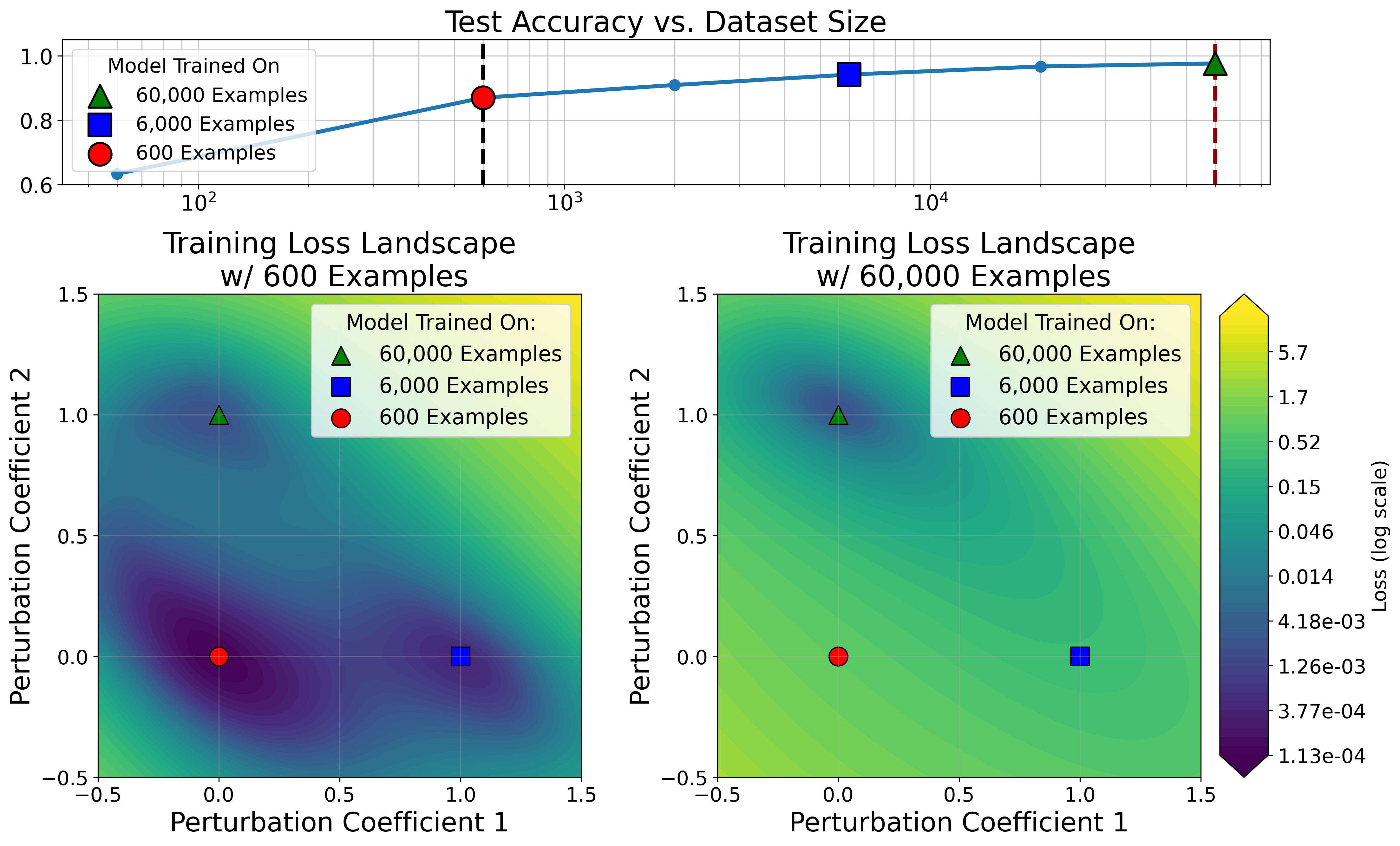
MNIST models trained on varying dataset size show optimizers tend to find minima with low loss in a wide parameter space.
For the last ~6 months, I've been working with two others doing AI research. We've worked on RL (LLMs & robotics), generalization, and ARC-AGI.
From our work we have produced a paper on generalization in deep learning (see this excellent short video my cofounder made for an overview). One theory of generalization is that gradient descent tends to find flat minima due to their large volumes, which generalize well. This theory does not explain why large datasets are necessary to achieve generalization. We show minima from models trained on large datasets are sharp in small dataset loss landscapes. This implies data or strong regularization which change the loss landscape are necessary for neural networks to generalize. We conduct a host of experiments measuring minima volume, a measure of both flatness and likelihood of being found from optimizers, including analyses of sharpness-aware minimization and grokking.
A unifying theme connecting our work is a belief in artificial general intelligence. As part of this belief, we opted not to build a product. We believe superintelligence is on the horizon, and any time spent building a product is time not spent studying the algorithms that will govern our world in the short future, for eternity ever after. Unfortunately, it is significantly more difficult to raise venture capital without revenue in the short-to-medium term. This is for a variety of reasons, some good, some bad:
- One VC mentioned that funding our lab is like giving us a grant. This is fair: if we share our research, we learn, but the corporation does not capture the value. We could all go find jobs and leave investors with nothing.
- All VCs are interested in (short-term) ROI, in my opinion, to a fault. There has never been a greater financial opportunity to fund research. It may take 5, 10, or 20 years, but scaled intelligence can provide unimaginable wealth. Be patient.
- Many AI teams not building a product are world-class. While we all have strong backgrounds, it is fair to prefer funding them over us.
With financial support difficult and AGI looming, we have decided, sadly, to close shop. Joining existing efforts strengthens our, and the efforts we join, chances of achieving AGI. It also gives us the opportunity to learn from mentors, rather than, as cofounders, peers.
Research Background & Inspiration
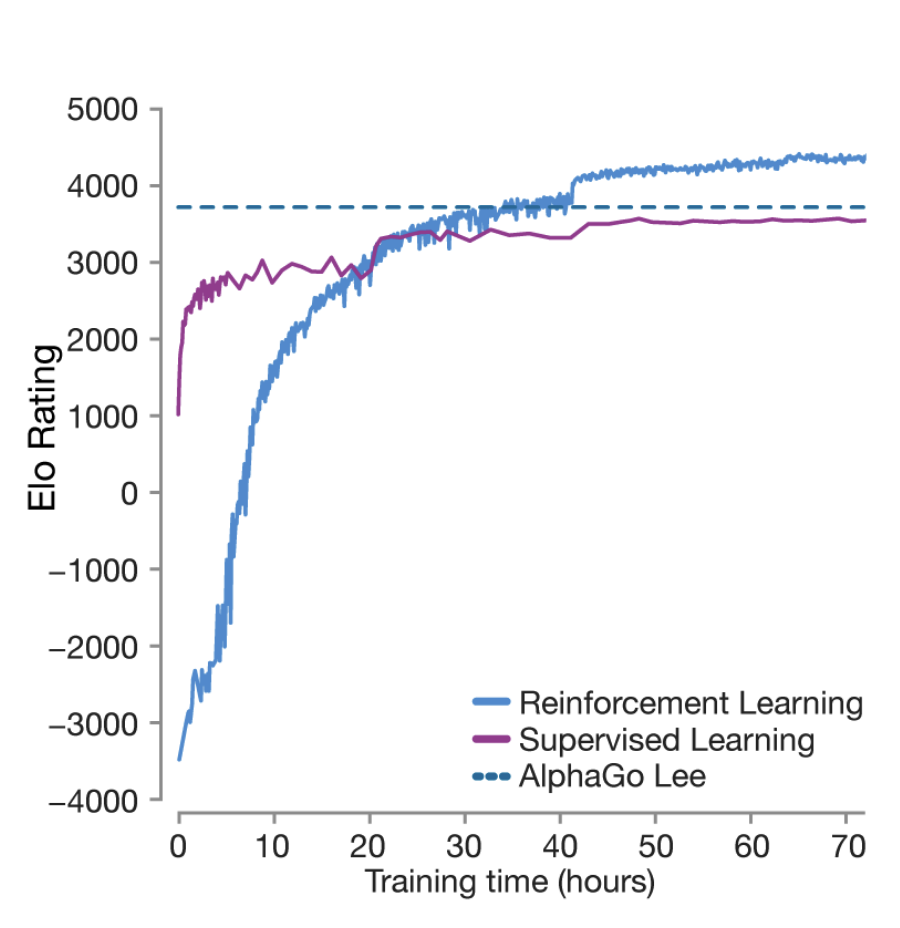
AlphaGo Zero surpasses AlphaGo Lee after 36 hours of training.
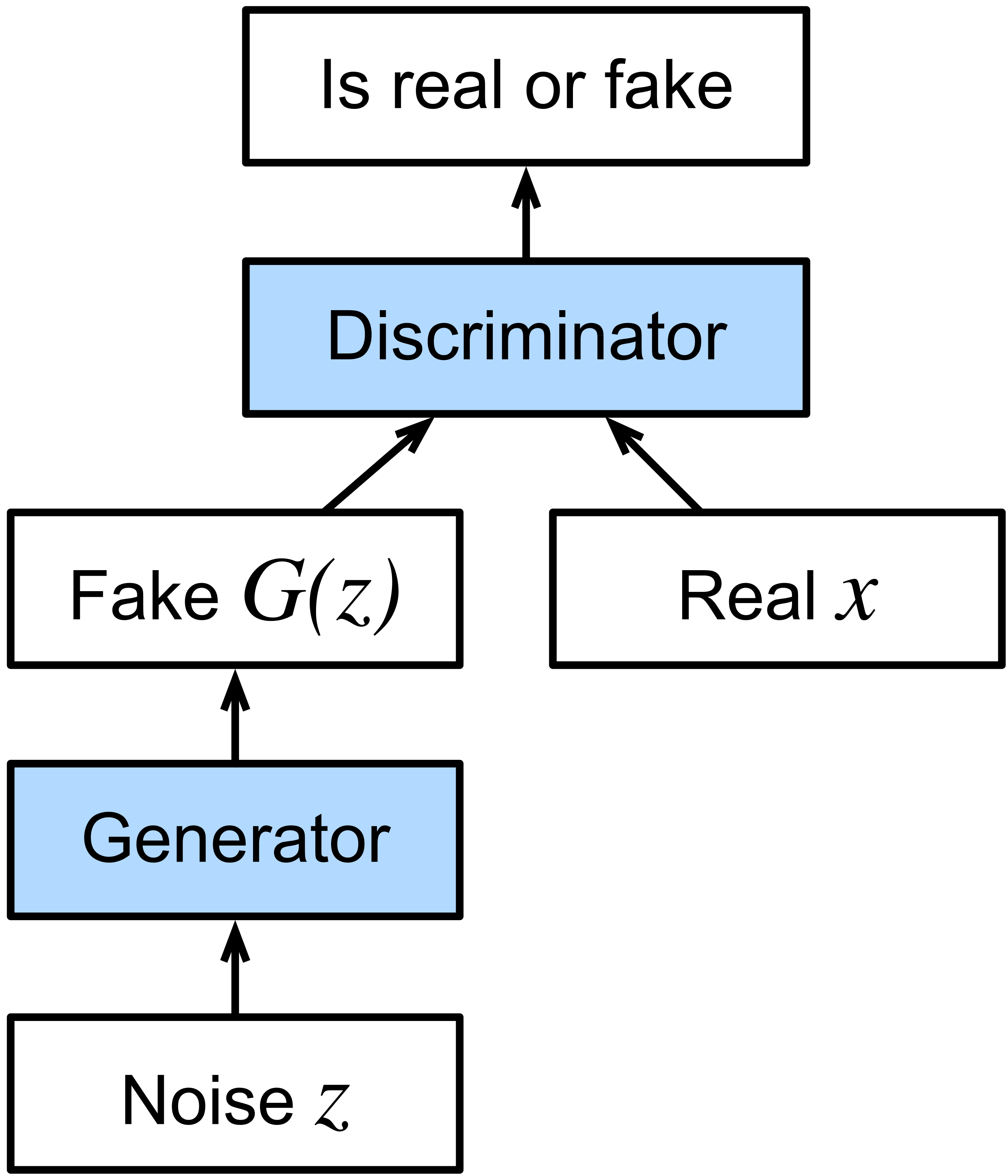
GANs leverage a discriminator to achieve a generative neural network.
In graduate school, I studied the design and analysis of algorithms, particularly, data structures. The beauty of data structure design is how little you have to work with. Rather than relying on math lemmas, most data structures are pure combinatorial cleverness. This is my favorite class of contest problems and the type of problem-solving in which I most excel.
There are many opportunities to leverage algorithm design in machine learning. My two favorite machine learning papers are GANs and AlphaGo Zero. GANs take advantage of flexibility in optimization objective. Rather than training a single neural network with a single objective, we compete two against each other with opposing objectives. These dueling networks allow leveraging classifiers to achieve generative networks.
AlphaGo Zero also employs clever algorithm design. Here, the insight is that by bringing MCTS into the training loop, we strengthen the reinforcement learning data. This allows forgoing the initial supervised learning phase, thus requiring no human prior, and makes training faster. In just 36 hours of training, AlphaGo Zero surpasses AlphaGo Lee, trained for several months.
This is the machine learning research I find most exciting. Bold algorithmic ideas that take advantage of existing strengths and flexibility to achieve new breakthroughs. The most recent such innovation known to the open research community is DeepSeek R1, which shows pure reinforcement learning can automatically add tokens to language models' chain-of-thought, improving reasoning capabilities.
It is surprising to me it took the open research community ~6 months from the release of OpenAI's o1 to repeat the result, particularly with such a simple recipe. Today, OpenAI and DeepMind are achieving some form of long chain-of-thought reasoning, evidenced by the submission times in OpenAI's recent ICPC World Finals all-kill. One team member mentioned "an ensemble of GPT-5s", with a special reasoning model to determine which solutions to submit and solving the final problem on the 9th try.

OpenAI all-killed the 2025 ICPC World Finals, with submission times reminiscent of human competitors.
Meanwhile, the open research community seems more focused on incremental improvements to existing LLM RL algorithms. We now have: GRPO, Dr. GRPO, DAPO, Lite PPO, GSPO, VinePPO, GMPO, CISPO, REINFORCE++, and countless others. All offer marginal improvements/tradeoffs over PPO and RLOO (REINFORCE, leave-one-out). I am more interested in how frontier models reason for multiple hours with a context window that fills in minutes, or how we might solve continual learning.
Adventures in LLM RL
I've spent the past 6 months mostly learning. My focus has primarily been LLM RL. I am not tied to language models nor to reinforcement learning, but large (multimodal) language models are currently our most powerful paradigm, and we have no example of superhuman capability without RL. I believe we need models to generate and learn from their own data to surpass the human ceiling and achieve superintelligence. I consider the current attitudes of Yann LeCun, Richard Sutton, François Chollet, and Andrej Karpathy towards LLMs and modern RL similarly to Einstein's attitude towards quantum mechanics. These individuals have unquestionably made groundbreaking contributions to the field, but this is simultaneously compatible with undervaluing the ideas that will transform its future.
I implemented GRPO from scratch in PyTorch (apologies for the messy code/repo, this is a hack, not production software). While the below pseudocode looks quite approachable, a full working implementation takes quite a bit more effort, with masking/padding/batching adding a significant amount of cruft that a higher-level API unfortunately does not currently handle (at least, not without sacrificing needed customizability). In pursuit of a research vision somewhat similar to Critique-GRPO, devised independently, my project turned into an exercise in RL stability.

GRPO Pseudocode. Doesn't look too bad, right?
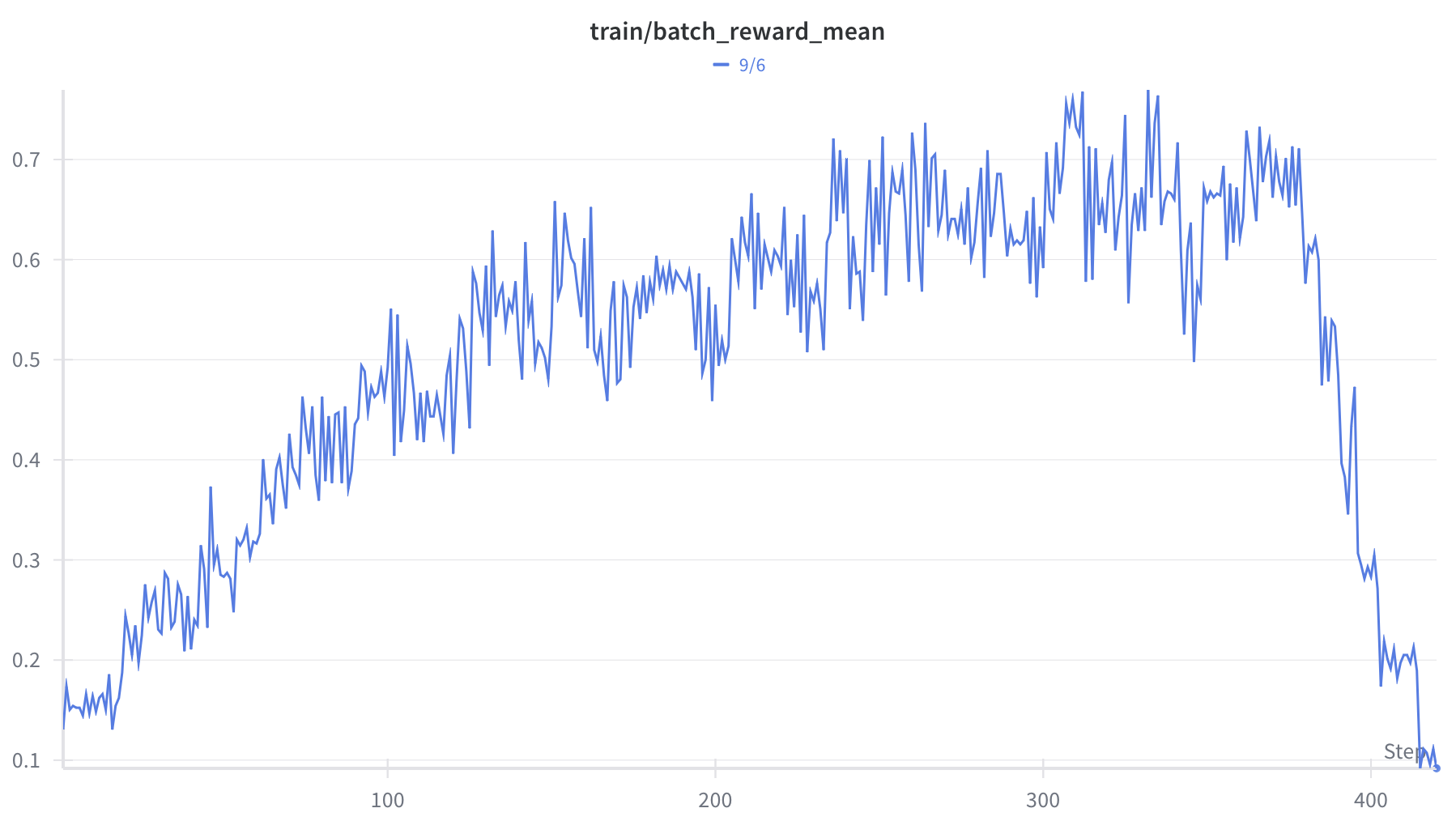
My GRPO implementation experiences reward collapse after convergence.
While succesfully training reasoning to convergence, after convergence, my script exhibits entropy explosion and reward collapse. Instability in LLM RL appears quite common, with numerous works (Thinking Machines blog, Feng Yao's blog, Tricks or Traps paper, recent FP16 paper making rounds on X) proposing various algorithmic or engineering fixes. I've been unfortunately unable to stabilize my script despite many attempts. VERL does not have the same stability issues on an equivalent workload.
Despite this setback, I have been able to train reasoning language models via PPO, GRPO, Dr. GRPO, DAPO, and Lite PPO. A few learnings:
- GRPO is a biased estimator of the policy gradient. In addition to the established effect this has on overweighting prompts with nearly-all-correct or nearly-all-incorrect responses, my experiments have also found this to cause partial-reward formulations to be much more likely to converge to local, but not global, optima. This is because standard deviation is invariant to scale: $\mathrm{std}(cX) = |c| \mathrm{std}(X)$. Response groups receiving only partial reward are treated the same as response groups achieving full reward.
- I trained Qwen3's reasoning and instruction-tuned (but not reasoning) model on the Countdown task (Game of 24). While both trained to convergence, the converged policies were substantively different, with the reasoning pre-trained model outputting far more tokens and the instruction pre-trained model iterating through possible equations, exactly how this paper describes.
- The exact training methodology, aside from my above criticism of GRPO, did not seem otherwise particularly impactful. Method and hyperparameters indeed impact the policy at convergence, but the differences are minor.
- On the other hand, prompt engineering of the training environment was very important. Some reasoning templates are harder to learn than others. VERL quickstart seems optimal: the model must output its final answer following four "#"s.
- (Smaller) language models still exhibit mistakes after convergence. For the countdown task, despite explicit instruction, the models I trained would often fail to use the provided numbers precisely once. For some reason they never managed to learn this.
- In Qwen models, <think> is an explicit token in the tokenizer, but the base and instruction-tuned models have never seen it before. When I instructed them to write reasoning in <think> markdown, the models would respond with bizarre text, due to being pushed out-of-distribution.
Research Vision
I am interested in broad algorithmic and "RL setup" ideas in LLM RL. More inspiration for this direction comes from classical reinforcement learning. Classical reinforcement learning algorithms offer more substantive changes/tradeoffs than today's tweaks on LLM policy-gradient methods, but the papers I find most interesting in the literature are those with broader ideas that apply to a variety of algorithms:
- Prioritized Experience Replay: Order experience buffer by most consequential episodes.
- Universal Value Function Approximators: Incorporate goals, not just states, into the value function.
- Hindsight Experience Replay: Learn achieved goals from given experience.
- A Distributional Perspective on Reinforcement Learning: Learning value distributions is more powerful than expected values.
- Go-Explore: Mapping a space is critical to learning in it.
Recent advancements in AI-generated video make one thing clear: gradient descent in deep neural networks can learn any distribution. However, the number of gradient steps necessary leaves a gigantic gap between the sample efficiency of humans and animals compared to our current algorithms. Can we learn to learn quickly? My claim says we can. This would produce not a knowledgable chatbot, but something more like an intern. An AI system that over time can solve any problem it is tasked with: a true replacement for human work.
A system of this form may operate on gradient steps when deployed (in contrast to today's models), or it might leverage a form of symbolic memory. It might be one model, or it might be several, perhaps with its own software stack. The solution will no doubt employ today's methods, but it will likely combine them in a creative way, much akin to how GANs created generative models from the tools available at the time.
In principle, I believe a system of this form will employ reinforcement learning. However, today's RL simply learns whether or not to repeat policy trajectories. Generalization happens in neural network function approximation at the model objective level: to produce the next step given previous steps. This is why it is so much less sample efficient than humans and animals. We must apply generalization on a coarser level to achieve biological learning speed.
Research Insights
Here is a strength and a flexibility of current LLMs which I believe can be harnessed toward greater capabilities.
-
Strength: In-Context Learning and the Power of the Prompt. Current research is largely split into gradient methods (most work) and prompt engineering (CoT, Reflexion, Alpha Evolve, ARC-AGI attempts, GEPA). These two communities are somewhat isolated from one another (though, arguably, o1 / Deepseek R1 are an example of fusion). This is unfortunate: context and gradient methods can and should both be leveraged. In-context learning provides sample efficiency not currently achievable with gradient methods. Gradient methods unlock capabilities context engineering cannot.
As language models have come to the forefront, we've seen a resurgence of evolutionary algorithms which "evolve" LLM context. I believe these methods to be inferior to reinforcement learning. Why not train language models to call other models? This sits at the same place as the higher-level evolutionary algorithm but leverages the current best techniques. Instead of evolving prompts, we get an ensemble of models with vastly expanded context (!).
Such an ensemble leverages both gradient and context methods, producing perhaps not a single model but a cohesive system. Done the right way, we may be able to leverage a resource of ample supply not currently utilized in today's approaches: disk space. Today's models use both training and inference compute, but are relatively small in memory footprint compared to the vast amount of information they are trained with.
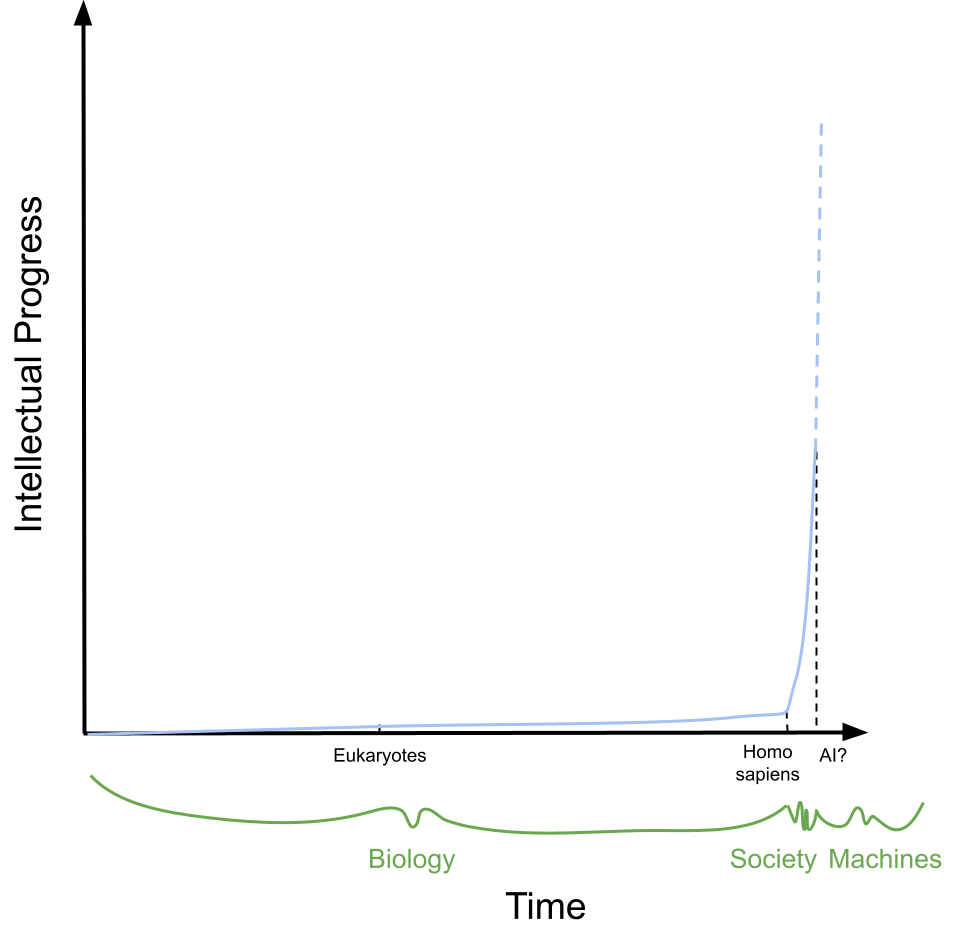
Intelligence on Earth.
On a final note to emphasize the importance of context, consider the following analogy with intellectual progress on earth. Over billions of years, intelligence on earth developed slowly, at the pace of biological evolution. With Homo sapiens, knowledge is now passed through generations, accelerating across human civilization. Biology, the vector of intelligence for the past ~4 billion years, has been replaced by society, offering progress at a much greater pace (the metaphor need not be carried out to a possible third phase—silicon intelligence—but shows its possibility).
The same can be true in machine learning methods. Gradient descent on deep neural networks has produced a form of machine intelligence. But it may ultimately be a spark towards a system that learns at a much greater pace, incorporating context. We should be creative in what ideas we pursue for future capability, not tied to a particular paradigm.
-
Flexibility: Language Models Predict Distributions. Auto-regressive language models predict distributions over possible next tokens. This is done for a variety of reasons, but in doing so, the model itself does not know precisely what text will come next. This makes for curious phenomena when planning future text, like in poetry. The model must simultaneously predict all possible continuations for the current writing. For models that have not undergone post-training, this quickly results in uncohesive text. However, for production models, it is rare for a model to start a block of writing it cannot finish properly (Suno AI lyrics, at least in earlier versions, may be an exception).
Regardless, the fact the consumer ultimately decides which path of the language model to take offers a wide design space of possible sampling methods. This is exploited by ARC-AGI LLM solutions (ARChitects, MindsAI, BARC, MIT), where inferring grid tokens is critical, symmetries are available, and greedy decoding does not necessarily give you the most likely solution grid. It appears a similar idea is leveraged in Google Gemini's DeepThink.
Less discussed (though it appears the aforementioned ARChitects do this exactly) is sampling from the product distribution of multiple models or the same model with different context. Suppose we have models $\pi_1$ and $\pi_2$ with contexts $\text{context}_1$ and $\text{context}_2$, where $\pi(o|\text{context})$ denotes the probability of producing token $o$ from model $\pi$ given $\text{context}$. We then sample token $o$ with probability proportional to $$ \pi_1(o|\text{context}_1)^\lambda \cdot \pi_2(o|\text{context}_2)^{(1-\lambda)} $$ for a specified hyperparameter $\lambda$.
I would be very curious what sampling from the product distribution of two frontier language models might look like (MoD suggests it's a promising direction). How would doing so affect performance on a benchmark? Regardless, this flexibility offers creative sampling methods that could be useful in algorithm design.
Research Ideas
Here are two concrete research ideas, the first of which I am actively pursuing. The second is probably too large of engineering scope for our current team.
-
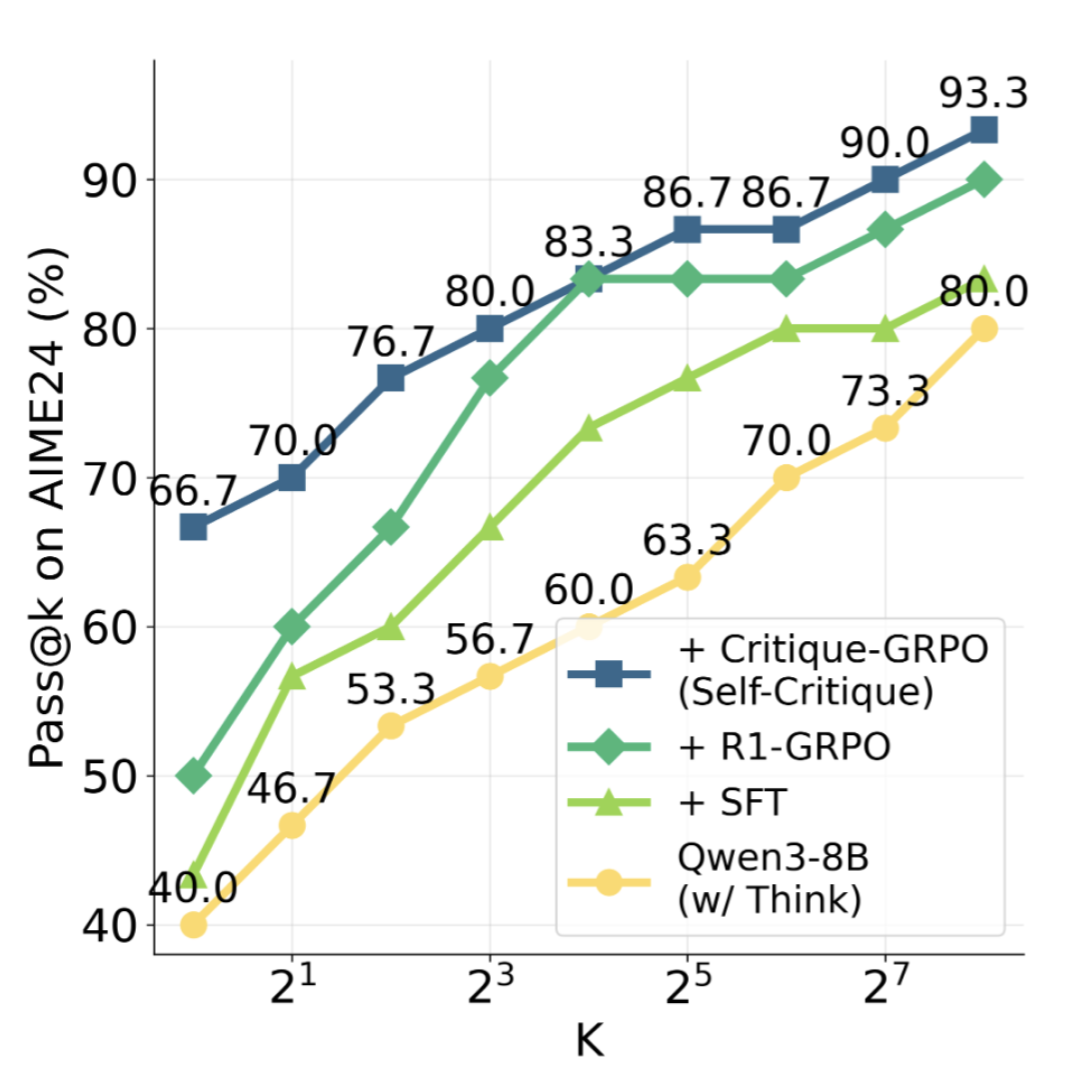
Critique-GRPO shows improvement over GRPO, SFT, and a general reasoning model on AIME24.
One insight from AlphaGo Zero is that reinforcement learning approaches can do much more than simply repeating rewarding trajectories. AlphaGo Zero's neural networks actually predict the outcome from MCTS given a board state, which is then used to inform the MCTS itself. A similar idea can be applied to LLM RL. While language models are trained to predict text, there is no requirement that this text be produced directly from the model. If we can improve the output of an LLM, then learn from the improved text, we stand to increase sample efficiency and learning speed, similarly to AlphaGo Zero.
A straightforward application of this idea is Critique-GRPO, an online LLM RL algorithm where models self-refine outputs after feedback. Their work shows refining output leads to modest gains in final performance.
While their research largely matches my original idea, there are ways to take it a bit further. One direction is to use the aforementioned product distribution. In RLVR, we generally have the correct answer on-hand. It would be interesting to train a model with reinforcement learning where we sample from the product distribution of it with two diferent contexts—one the original prompt, and another the original prompt with the correct answer provided. We could start $\lambda$ at something like $1/2$ and anneal it during training until the model learns with no influence from the context with the answer.
We should see fast learning and a far greater percentage of rewarded outputs. It may allow circumventing curriculum learning and solving harder problems than were previously approachable.
-
While Critique-GRPO shows a methodology like the above may also improve final performance, the metric I am primarily targetting is sample efficiency. The field cares more about final performance.
Final performance appears to be more influenced by model capacity than training modality. Somehow, even after IMO Gold (DeepMind, OpenAI) and ICPC WF all-kill (OpenAI), many researchers aren't convinced reinforcement learning improves model capability beyond the base model.
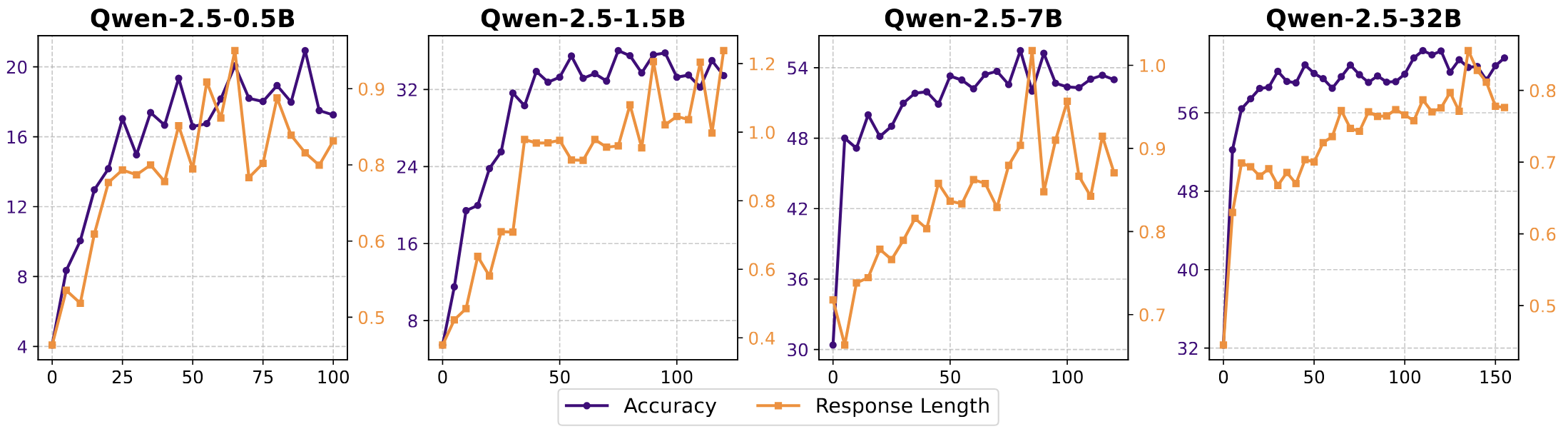
SimpleRL-Zoo compares RL improvement on a reasoning dataset across model sizes. X-axis is steps, response length is in thousands.
There is no disagreement that larger models are more capable. Unfortunately, neural scaling laws indicate this relationship is logarithmic, so that simply scaling up is eventually cost-prohibitive (think GPT 4.5—slow and expensive).
Mixture of experts, with many experts, is one way to increase capacity without slowing inference. I am curious if this can be applied at the post-training layer, via LoRA adapters. The efficiency at which LoRA can fine-tune, particularly for RL, suggests low-rank matrix factorizations may have more use throughout model architectures. Regardless, they may have direct use in increasing capacity in post-training.
While token-level routing, like in MoE, using LoRA adapters, would in theory be possible, a more-promising direction might be to either switch the inference model with a special output token or to leverage ensembles of models that call each other.
This approach brings several advantages over MoE. For one, LoRA adapters are tiny. This potentially means more model capability for less VRAM. Also, routing on a coarser level may permit storing unused adapters on disk or simply make routing more efficient. A final advantage is in methods: LoRA adapters are clonable. It might be possible to teach a model when to duplicate or to grow a population of adapters incrementally, initialized to already-trained weights.
Conclusion
Thank you for reading. I am currently on the job market for member of technical staff positions in post-training. In the meantime, if any of these ideas intrigue you, send me a note and collaborate with us. We have an open Discord.
Before ending, I'd like to briefly discuss AI safety. As we approach superintelligence, AI safety is paramount. I do not feel risk is high with our current models and deployment pipeline. Creating something like I've described here as "the intern" would introduce much greater risks, especially if production model weights are allowed to change. I believe these risks are not unsurmountable and should be addressed in tandem with technical development. I believe mechanistic interpretability should be pursued independently alongside capabilities research. We understand the artificial brains we are creating better than we do our human brains. That is encouraging for the fate of humanity.